Hugging Face - O playground do GenAI Data Scientist
Lipie Souza20 de set. de 20234 min de leitura124 visualizações
Já existem muitos favoritos no mundo entre as startups impulsionadas para a corrida à IA Generativa, grande parte dos investimentos de aceleração da YCombinator já tem como destino estas empresas que despontam rapidamente e ganham espaço nas discussões e experimentos de muitos entusiastas na área. A Hugging Face, ao lado de outros objetos de análise neste blog, também recebeu quantidades volumosas de investimentos. E tem um motivo nobre, eu explico aqui: Esta empresa vem reunindo, curando e facilitando a disponibilização de algoritmos para Machine Learning com base em modelos pré-treinados, facilitando e muito, o trabalho de qualquer Cientista de Dados, e principalmente, impulsionando o contexto de adoção de Generative Pre-trained Models, dando um boost na criação de modelos customizados para os mais diferentes problemas de Machine Learning. Neste artigo eu apresento os benefícios no dia a dia de uma pessoa da área de dados e trago alguns exemplos que ajudam a tangibilizar-los. 😉
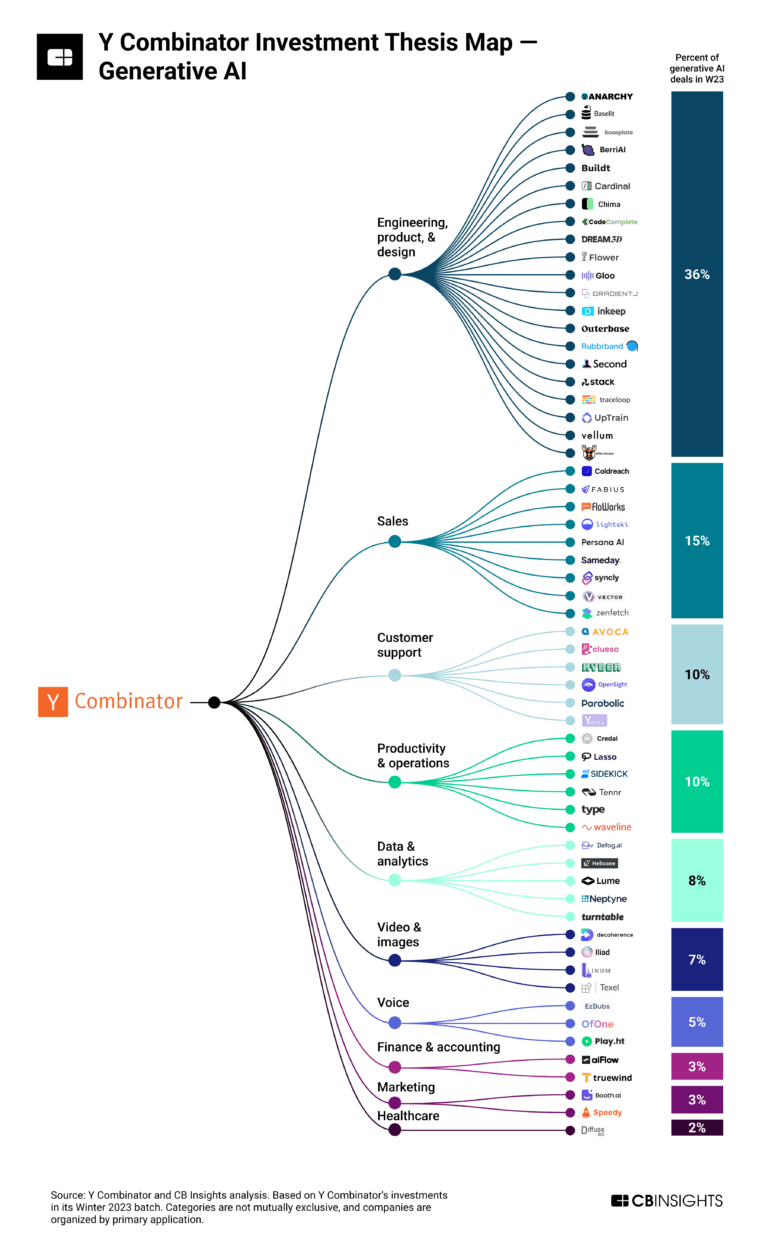
Acima o mapa de investimentos de aceleração da YCombinator em IA Generativa.
Primeiro precisamos relembrar melhor o contexto dos GPTs, são modelos Transformers pré-treinados com vastas quantidades de dados textuais, os transformers diferentes do modelos tradicionais entendem a relação semântica entre as palavras a partir de um processo de treinamento baseado em tokenização que distingue o sentido de cada token a partir de métodos estatísticos. O que isso quer dizer? Que modelos pré-treinados são uma base linguística considerável em que você consegue incorporar novos significados de um jeito muito mais fácil, sem precisar treinar um modelo do zero. Isso salva aquelas vastas horas onde engenheiros e cientistas de dados tratam e transformam suas bases iniciais de dados e depois precisam testar inúmeras formas de treinamento até atingir baixas taxas de erro. Com um modelo pré-treinado basta incorporar um dataset a parte, e esse processo de inclusão é bem mais corriqueiro, pois temos uma técnica chamada embeddings que basicamente traduz esse conjunto de dados a “linguagem” dos transformers, isto é, vetores de armazenamento semântico. Relembre este processo aqui neste post.
Estes vetores são nada mais nada menos que um bolsão de conhecimento a parte que LLM incorpora em sua base pré-treinada. Bom, e como o Hugging Face entra nessa jogada? Eles atuam justamente disponibilizando os algoritmos necessários para “juntar” estes conjuntos de dados a modelos pré-treinados. Há diferentes algoritmos para distintos focos, desde aplicações de reconhecimento de imagens, análise de sentimento, geração de texto a até modelos preditivos (sim, existem LLMs para as famosas aplicações de ML para séries temporais, que economistas e analistas de risco adoram e são queridinhas do mercado). Isso mesmo, no Hugging face você já encontra modelos pré-treinados para análises preditivas também (Eu fiquei em choque quando descobri isso). Esta é uma evolução importante dentro do campo da IA, uma vez que você não precisará mais ficar testando variáveis de regressão linear, perceptrons alinhados em um modelo de Deep Learning tentando fazer mágica para conseguir um bom fitting, pois irá contar com um GPT especialmente treinado em reconhecer padrões em séries temporais. Ufa, me fez lembrar de projetos antigos onde precisávamos chegar a preços de venda ótimos, mas o trabalho para construir o modelo era hercúleo e muito artesanal, vamos dizer assim. 😓
O que todas essas mudanças impulsionadas pela facilidade que comunidades como o Hugging Face trazem para esta área? Que muitas vezes não precisaremos mais aprofundarmos no código (muitas vezes em Python) para poder construir redes neurais para problemas específicos. A tendência no mundo de TI para migração de arquiteturas low-code que já é realidade em muitas áreas está ganhando espaço na ciência de dados também. Não quer dizer que o especialista em em TensorFlow, PyTorch e outras bibliotecas para ML vá perder potencial, pois ter conhecimento a baixo nível de código é sempre um diferencial competitivo na hora de resolver problemas complexos ou até mesmo para trazer uma dose de personalização a bibliotecas consolidadas. Mas é preciso alertar que abrir a cabeça para adoção de algoritmos open-source e frameworks no ou low-code ajudam e muito a ganhar velocidade na implantação de projetos de Machine Learning. A chave é combinar o melhor dos dois mundos: adotar algoritmos e estruturas open-source e low-code para acelerar a implementação de projetos de Machine Learning.
A revolução está acontecendo, e a porta para a inovação está aberta a todos! Vamos somar forças unindo especialistas e generalistas, desenvolvedores, cientistas e gerentes, neste momento, o que precisamos é de maior experimentação e intercalação entre papéis e estruturas menos rígidas. Criatividade só se constrói como uma brincadeira no playground e com Hugging Faces. 🤗
Comentários (1)
1 comentário no site original