Using LLMs for Data Transformation (ETL) in Data Lake Projects
Lipie SouzaFeb 12, 20244 min read58 views
Another interesting use case that combines natural language processing (with cognitive inference) with structured data processes
In February 2024, I will complete 10 months of studies and experiments on Generative AI. I have exchanged ideas with many people, launched an experimental product, understood certain limitations of the technology - many of which I believe are temporary, and over time I have come to a more informed and realistic perspective on how it will be adopted.
Now I am faced with another use case, which seemed obvious due to the intrinsic characteristics of LLMs, but had gone unnoticed. Large Language Models are excellent at analyzing structured data from a linguistic perspective, just as we humans do when we think - in the case of LLMs, obviously still in a very rudimentary way, with very little capacity to chain hypotheses for more complex rationalizations. However, there is one activity that fits perfectly into this limited scope: the act (or can I say the cornojob? 😢) of interpreting relational data tables about certain business processes and transforming them into multidimensional data with the proper keys and their respective associated facts and events. Obviously, there are tools that perform the transformation itself, but they necessarily require a human analyst to understand the relationships/contexts between each table, field, data type, etc. This text is precisely an analysis of how feasible it is to put a language model to do this for us, and the starting point is this article from September 2023 from the IEEE.
A study led by renowned universities such as the University of Arizona and the University of Tianjin, with the support of Microsoft, demonstrates that it is possible for a LLM (Large Language Model) to understand a complex knowledge domain involving databases and transform them efficiently for Big Data/Data Lakes projects. The study focuses on knowledge bases about building energy efficiency, with the aim of unifying, normalizing and centralizing data from different sources to create a global database for energy monitoring studies. The initiative is from the Institute of Electrical and Electronics Engineers (IEEE). The study is relevant in the sense that we already know about the limitations of LLMs for complex mathematical calculations, however, since they are simplified and repetitive numerical transformations, the result demonstrated was 96% accuracy regarding 105 data schema transformation problems. Below, three examples of transformations that would be demanded from the constructed algorithm, the SQLMorpher.
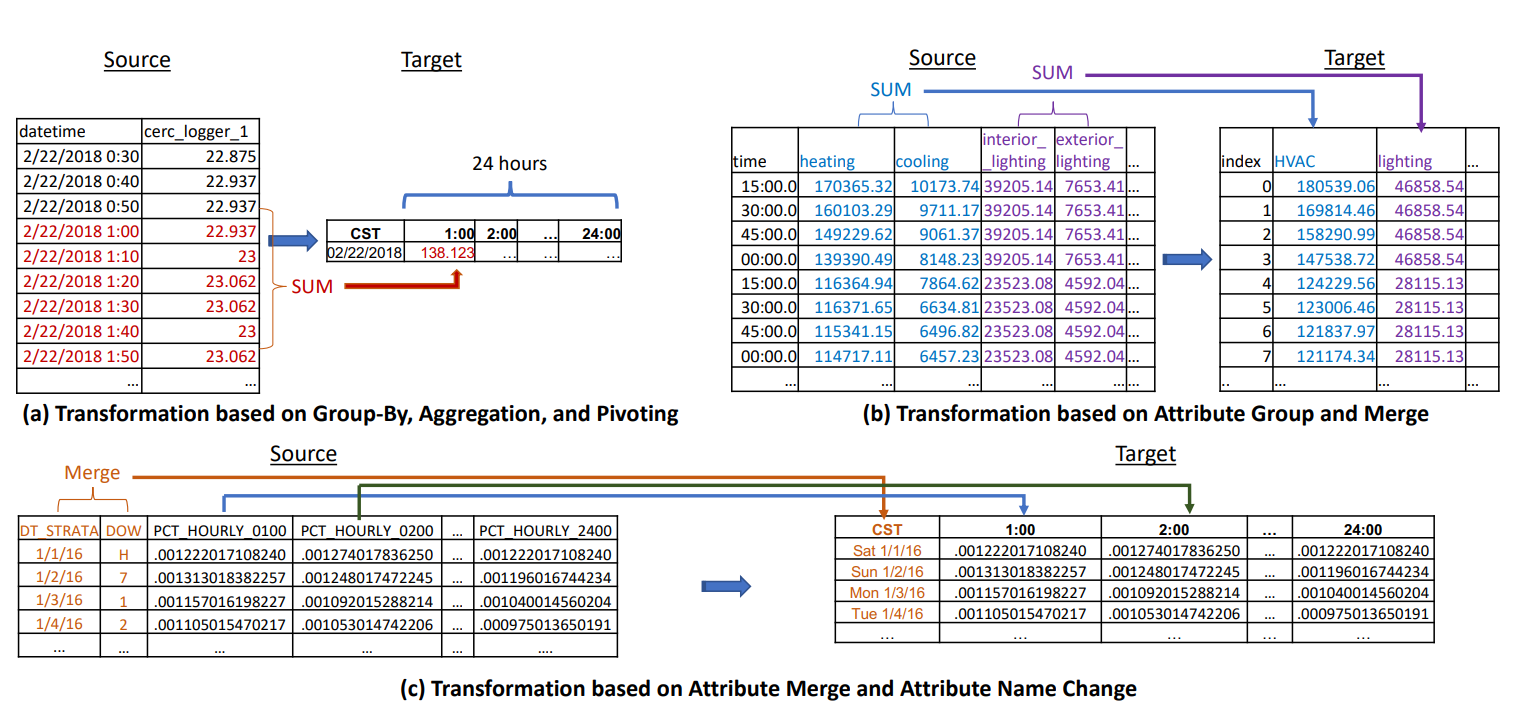
The algorithm in question was trained using techniques already explored in this blog. The training dataset consists of past SQL transformations, contextualized by prompts that explain the desired task, the SQL modifications between the schemas, the domain of knowledge used, and the correct result evaluated with its justification. Using the embedding technique already explained in this article, a Vector Database (Faiss) was created. This training dataset enabled an interactive process in which the prompt was gradually modified until the expected transformation result was obtained. The great novelty of this article, in relation to LLM studies, is the use of interaction loops for prompt optimization. This strategy seems interesting when the expected results are correctly mapped and seems easily replicable for applications that involve code production. With this technique,
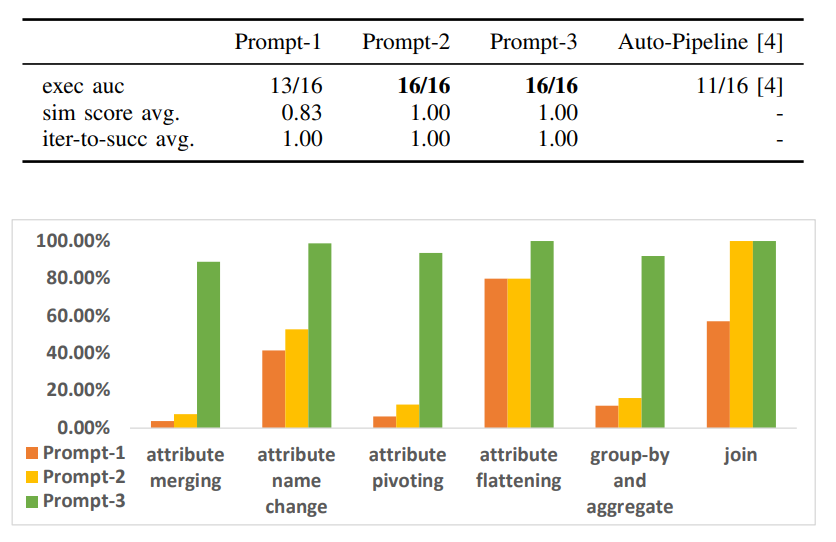
These experiments raise new questions about the use of LLMs, but they also point to possible applications in the short and medium term. Based on the results of this study, we can make a few statements:
1. LLMs need refinement and context to perform well in specific problem analyses. This means that specially trained LLMs will be needed for most operational work domains currently performed by IT, Finance, Marketing, and other area analysts.
2. Tasks that involve linguistic analysis interspersed with simple mathematical problems are excellent candidates for automation by LLMs.
3. These experiments are a harbinger of what is already underway in the product teams of large corporations such as Google, Amazon, and Microsoft. It is only a matter of time before "powered by LLMs" applications begin to gain ground in the coming months and years.
Until then, we will live with a mix of traditional applications with a dash of "Generative AI". These applications will partially optimize the process flows present in companies today. However, only with specially trained LLMs will we have an exponential leap in productivity in the operational work arrangement. Let's follow! And let's keep experimenting.😎
Comments (0)
- No comments yet. Be the first!