Hugging Face - GenAI Data Scientist's Playground
Lipie SouzaSep 20, 20234 min read107 views
There are already many favorites in the world among the startups accelerated for the Generative AI race, and a significant portion of YCombinator's acceleration investments are now directed towards these rapidly emerging companies that are gaining prominence in discussions and experiments among many enthusiasts in the field. Hugging Face, alongside other startups analyzed in this blog, has also received substantial amounts of investment. And there's a good reason for it, which I'll explain here: This company has been gathering, curating, and facilitating the availability of algorithms for Machine Learning based on pre-trained models, greatly simplifying the work of any Data Scientist and, most importantly, driving the adoption of Generative Pre-trained Models, boosting the creation of customized models for a wide range of Machine Learning problems. In this article, I present the day-to-day benefits for someone in the data field and provide some examples to help illustrate them. 😉
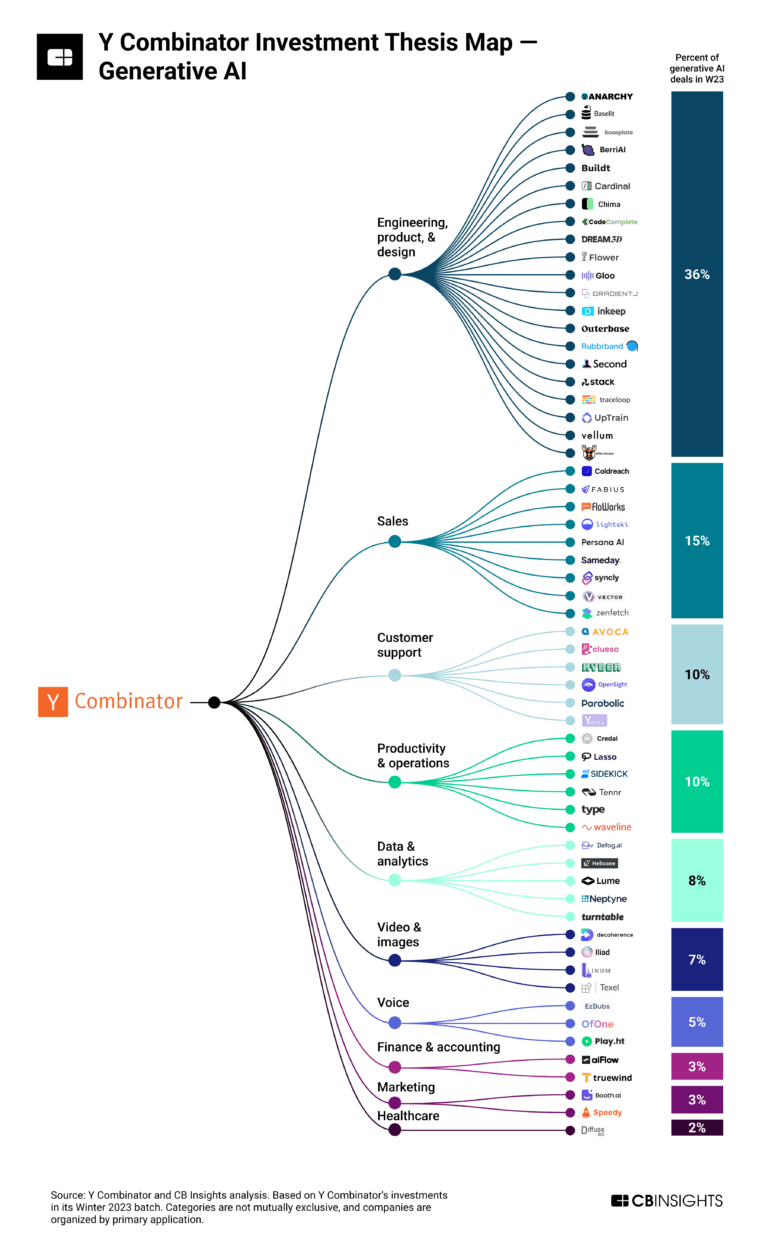
Above is the investment map of YCombinator in Generative AI.
First, let's recap the context of GPTs. They are pre-trained Transformer models with vast amounts of textual data. Unlike traditional models, Transformers understand the semantic relationship between words through a tokenization-based training process that distinguishes the meaning of each token using statistical methods. What does this mean? Pre-trained models provide a substantial linguistic foundation where you can easily incorporate new meanings without the need to train a model from scratch. This saves the extensive hours where engineers and data scientists preprocess and transform their initial data sets and then need to test numerous training approaches to achieve low error rates. With a pre-trained model, you simply incorporate a separate dataset, and this inclusion process is much more straightforward because we have a technique called embeddings that essentially translates this dataset into the "language" of Transformers, i.e., semantic storage vectors. Review this process here in this post.
These vectors are nothing more than a separate pool of knowledge that a Large Language Model (LLM) incorporates into its pre-trained base. So, how does Hugging Face fit into all of this? They operate precisely by providing the algorithms necessary to "merge" these datasets with pre-trained models. There are different algorithms for different purposes, ranging from image recognition, sentiment analysis, text generation, to predictive models (yes, there are pre-trained LLMs for the popular machine learning applications for time series that economists and risk analysts love and are market favorites). That's right, at Hugging Face, you can already find pre-trained models for predictive analyses as well (I was shocked when I discovered this). This is a significant advancement in the field of AI because you no longer need to test linear regression variables, aligned perceptrons in a Deep Learning model trying to work magic to achieve a good fit. Instead, you can rely on a GPT specially trained to recognize patterns in time series. Phew, it reminds me of old projects where we needed to arrive at optimal selling prices, but the effort to build the model was Herculean and very artisanal, so to speak. 😓
What do all these changes driven by the ease that communities like Hugging Face bring to this field mean? It often means that we no longer need to dive deep into code (often in Python) to build neural networks for specific problems. The trend in the IT world towards low-code architectures, which is already a reality in many areas, is gaining ground in the field of data science as well. This doesn't mean that experts in TensorFlow, PyTorch, and other ML libraries will lose their potential, as having low-level code knowledge is always a competitive advantage when solving complex problems or even adding a dose of customization to established libraries. However, it's essential to recognize that opening up to the adoption of open-source algorithms and low-code frameworks can significantly accelerate the implementation of machine learning projects. The key is to combine the best of both worlds: adopting open-source algorithms and low-code structures to speed up the deployment of machine learning projects.
The revolution is happening, and the door to innovation is open to everyone! Let's join forces by bringing together specialists and generalists, developers, scientists, and managers. At this moment, what we need is more experimentation and flexibility in roles and structures. Creativity is best nurtured as a playful endeavor in the playground, with the help of tools like Hugging Face. 🤗
Comments (0)
- No comments yet. Be the first!