Embbedings - A powerful technique to chat with your data
Lipie SouzaJun 28, 20236 min read121 views
For those who read the last blog post here, I presented the differences between the techniques that allow you to customize a language model for specific purposes. Each of the techniques: Prompt Engineering, Embeddings, and Fine Tuning should be chosen according to the purpose of adapting the model. In this article, I will delve into the use of the Embeddings technique, demonstrating how it can be a powerful ally in the construction of conversational products (Chatbots), as a tool to interact, understand, and consolidate knowledge through the act of conversing with this embedded dataset in an LLM, added to a vector base. In this article, I will strike a balance between the macro concept and technical depth and provide a tip for developers on duty, perhaps encouraging them to experiment with this new technique. The first idea I would like to discuss is that language models like GPT3/3.5 have been trained on vast amounts of data available on the internet. However, precisely because of this, they are shallow and not factual (not to say deceitful) when it comes to delving into a specific subject. But here we go, they are designed to appear true, so they lie to match what they are asked. The point here that many overlook is that they can be coupled with other databases (yours, for example, or other public databases) and immediately become experts in a specific knowledge, greatly enhancing their factuality in that domain where they have been incorporated. (As I demonstrated in the use case of Clipping GPT, for those who haven't seen it, here is the link to the article).
This technique allows the LLM to understand that an additional knowledge base has been added to it and that this base is more relevant than the general implicit knowledge it was pre-trained on (hence the acronym Generative Pre-trained Model), as they are pre-trained, generalist models that can be expanded according to the intended purpose. And how does this model consume new information? Through vector bases by default! This is because, as language models, they do not directly understand CSVs, text documents, graphs, etc. Instead, they understand semantic correlations between signifiers (words) - that is, the statistical correspondence between them. And vector models are exactly that, arrangements in space that map whether a word X is semantically close to another word Y and how they correlate with another word Z.
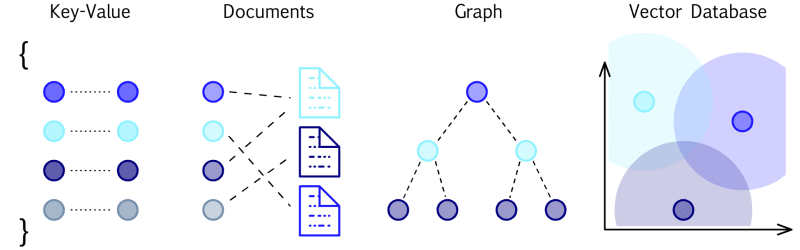
The embedding technique is precisely used in natural language processing and maps words or phrases from the vocabulary to real-number vectors. This reduces the dimensionality of categorical data and is an effective method for adding structure to raw data. The resulting vectors capture the semantic context of the signifiers: words that are semantically similar have embedding vectors that are close in the vector space, and how they relate to each other, verbs, adjectives, etc., are also mapped in this arrangement. In summary, every time you want to add new knowledge bases to an LLM, you need to transform them into a vector base. There are ready-to-use libraries for this purpose, such as Pinecone.. Pinecone has been gaining traction and establishing itself as the leading (if not the only) player in this context, and they adopt the following purpose: "The Pinecone vector database makes it easy to build high-performance vector search applications. Developer-friendly, fully managed, and easily scalable without infrastructure hassles."
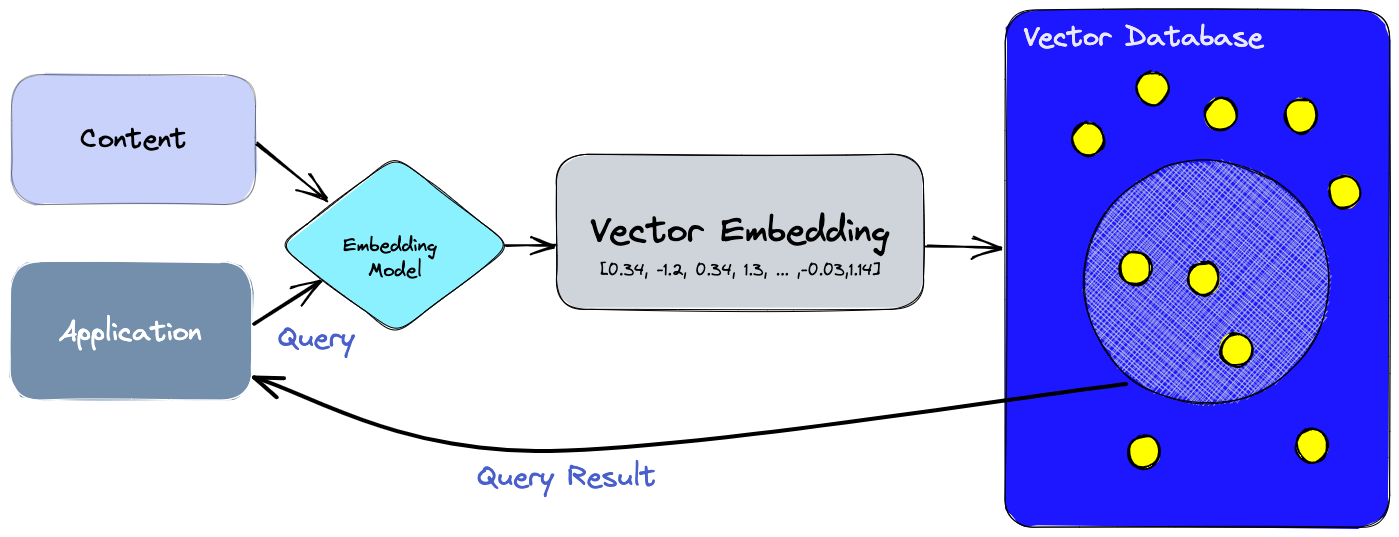
What Pinecone ultimately provides is a ready-to-query vector base from the data you have incorporated. Once you have constructed your vector base, adding it to a GPT model is a simple task, just three or four lines of code, using ready-to-use libraries from OpenAI, Pinecone, and LangChain, which have been discussed in this blog before. It is precisely this intermediary that "adds" your vector base to the LLM model, creating this customized application. In this article, you will find the base code so that you can play around in your Linux terminal. Vade Mecum Chatbot 🥸 To try to make this concept tangible, let's consider the following application: a chatbot that allows you to interact with and understand the Vade Mecum, the bible of Brazilian law. With this chatbot, instead of having to open the Vade Mecum and search for a specific topic or law, you can simply have a conversation with the book. Sounds crazy, right? Well, this is not the same as searching, as in semantic search, you can ask questions like, "Is there any law that can help me think about condominium implementation? Please list the necessary jurisprudence for reading," and the semantic search will provide you with a precise response. It's quite different from a simple "Ctrl+F". It's like having an agent in front of the book, making your life easier.
To build this chatbot, you could follow these steps: Download a free version of the Vade Mecum PDF available on the website of the Brazilian Federal Senate, convert it into text using one of the free online conversion tools. Install the OpenAI, Pinecone, and Langchain libraries, add your OpenAI API key, transform the text of the Vade Mecum into a vector base using the straightforward methods provided by Pinecone, and use LangChain to connect everything, providing an endpoint for you to connect your chatbot. Hey, developers, shall we make some money? Unfortunately, I don't have the skills to build this experiment because while GPT helps me learn a lot, it doesn't replace everyone's expertise and experience.
For corporate use, imagine conversing with the vast amount of data produced in hundreds, if not thousands, of isolated databases and dashboards that don't generate any insights on their own.
For data science, it's the same story. Scientists immerse themselves in trying to build techniques that help extract, manipulate, and real-time summarize the emerging trends in the network. Vector bases can represent these analytical premises and are easily expandable and updatable. It's possible to create applications that feed in real-time from the knowledge being disseminated across the network, and you can converse with these applications to generate briefings on these events. The way we interact with knowledge is going to change significantly in the coming months and years. We will have cognitive agents as allies. Let's make good use of them, not become lazy or alienated by the convenience (which will undoubtedly come at a price), and let's continue to share this knowledge for the better development of the internet, companies, and our applications. Until next time.
😎 Bonus: Who has tried the Noteable plugin for ChatGPT Plus? The plugin is still in testing but it already helps you create comprehensive visualizations and analyses from raw data using only Prompt Engineering. Check-out a use case here.
Comments (0)
- No comments yet. Be the first!